1-2 iulie 2021, participare la Conferința Internațională The Future of Education, ediție virtuală
În zilele de 1 și 2 iulie 2021, membrii echipei DACRE au participat la cea de-a 11-a ediție a Conferinței Internaționale The Future of Education (ediție virtuală). Aceasta face parte din seria de conferințe Pixel International Conferences, ce aveau loc înainte în Florența.
În pofida limitelor impuse de pandemie, eforturile conjugate ale membrilor echipei – Roxana Rogobete, Mădălina Chitez, Valentina Mureșan, Bogdan Damian, Adrian Duciuc și Claudiu Gherasim, din cadrul Universității de Vest din Timișoara, și Ana-Maria Bucur, de la Universitatea din București – au dus la crearea lucrării Challenges in compiling expert corpora for academic writing support (Provocări întâmpinate în alcătuirea unui corpus de tip expert pentru susținerea scrierii academice). Mai jos veți găsi și alte detalii despre lucrare și despre conferință.
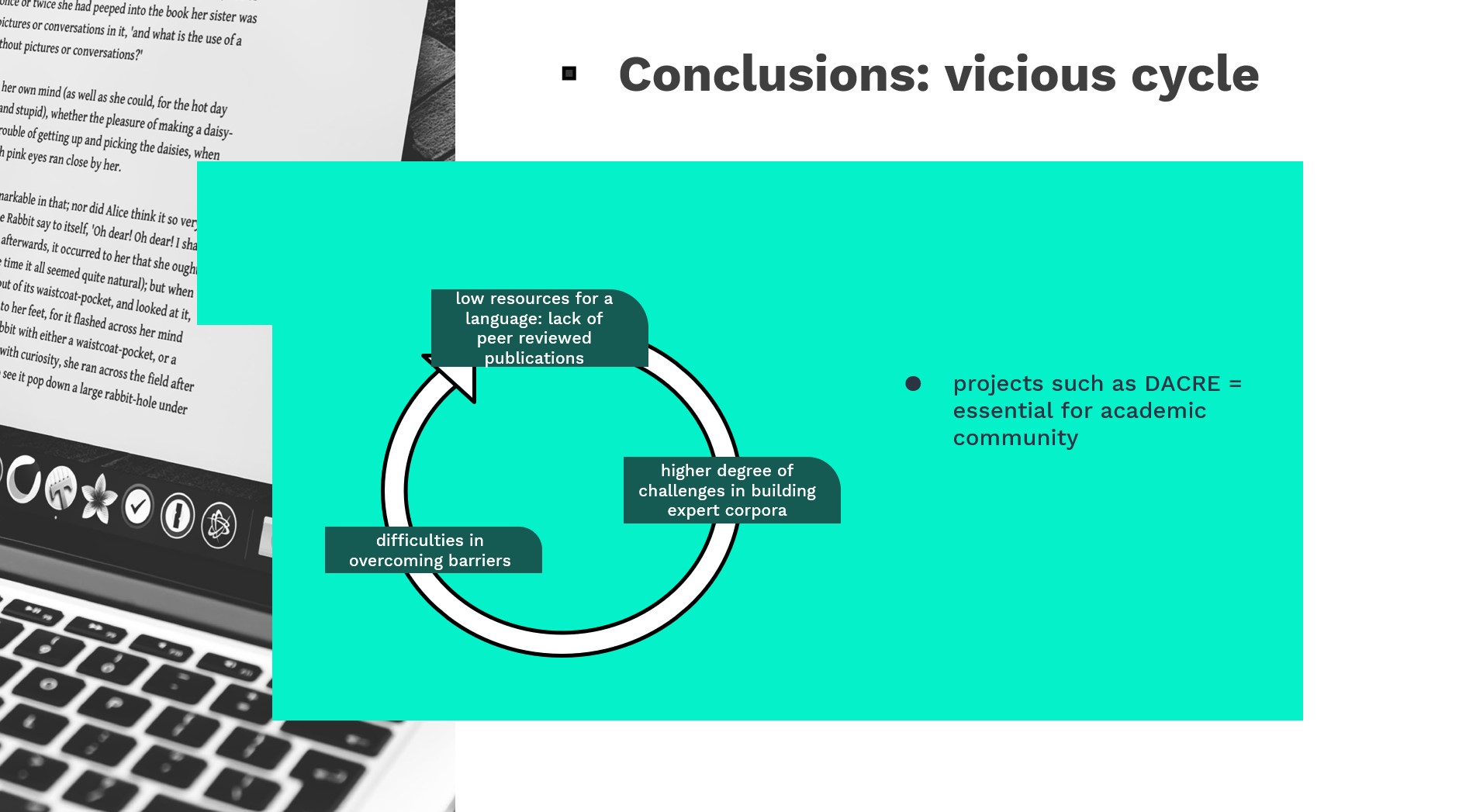
Rezumat: Lucrarea de față analizează unele provocări pe care unii cercetătorii români le-au întâmpinat în alcătuirea corpusurilor de tip expert pentru scrierea academică specifică disciplinei. Acest tip de corpusuri este util în domeniul predării și cercetării scrierii academice pentru limba română ca limbă maternă și limba engleză ca limbă secundară. Deoarece multe programe de studii din România sunt predate și în limba română (de exemplu, IT, Științe politice, Economie), iar engleza este considerată de mulți ani ca principala lingua franca din spațiul academic (Mauranen & Randa 2008), majoritatea lucrărilor academice relevante sunt scrise în engleză. În plus, lucrările scrise în engleză au un impact mai mare. Studiul se bazează pe analiza contrastivă a unui corpus bilingv alcătuit în cadrul proiectului DACRE (Scriere academică specifică disciplinei în limbile română și engleză: modele de analiză contrastivă bazate pe corpusuri lingvistice). Acest proiect a început în 2021, fiind finanțat de către Unitatea Executivă pentru Finanțarea Învățământului Superior, a Cercetării, Dezvoltării și Inovării (UEFISCDI). În cadrul acestuia ne propunem să popularizăm corpusurile în învățământul superior și să creăm instrumente digitale și modele metodologice folositoare pentru comunitatea națională și internațională de cercetare în domeniul lingvisticii. Scopul acestui proiect este să prezinte caracteristici lingvistice și retorice esențiale pentru fiecare disciplină (vezi Boettger 2016) și pentru fiecare varietate lingvistică (limba română, limba engleză ca limbă maternă și ca limbă secundară), care vor fi extrase din articolele științifice supuse procesului de peer-review. În faza de început a procesului de alcătuire a corpusului, când s-au evaluat resursele lingvistice care urmează să fie în corpus, au apărut mai multe provocări. De exemplu, pe plan lingvistic, aceste resurse nu sunt consecvente (vezi Yilmaz și Römer 2020). Alte dificultăți pe care le-am întâmpinat au avut legătură cu disponibilitatea informațiilor (cele gratuite sau cele pe bază de abonament), cu lipsa de resurse pentru anumite eșantioane ale corpusului, cu modul în care „autorii multipli” afectează stabilirea textelor de limbă maternă și cu aspectele legale, una dintre cele mai importante probleme (cum ar fi drepturile de autor). Prin descrierea, compararea și analizarea piedicilor existente în procesul colectării de date, propunem un model pentru alcătuirea unui corpus de tip expert în limba engleză vs. alcătuirea unui astfel de corpus în limbile cu puține resurse, cum este limba română.
Pentru a vedea programul conferinței, faceți click aici.
Articolele finale pot fi consultate aici.
Prezentarea echipei poate fi urmărită aici, iar articolul integral este disponibil aici.
Alte informații despre conferință se pot găsi aici.
Afișul evenimentului:

Iată câteva slide-uri din prezentarea susținută de echipa DACRE:
Roxana Rogobete, Mădălina Chitez, Valentina Mureșan, Bogdan Damian, Adrian Duciuc, Claudiu Gherasim, Ana-Maria Bucur, Challenges in compiling expert corpora for academic writing support


Concluzii: