What is expert writing?
How do scholars acquire/improve their academic writing skills? In general, there is a theoretical gap in terms of identifying linguistic patterns across field-specific academic texts. The Romanian writing cultures, for example, are scarcely researched (Baniceru & Tucan, 2018), both in Romanian L1 and English L2, especially from a data-intensive perspective. As is the case with other languages, for the Romanian context, there is little research-based academic writing practice: scholars compensate for this by using observational models delivered by textbooks/classroom research papers. Systematically, at a larger scale, such practice can be supported and complemented by the use of expert writing corpora.
| Broadly defined, expert corpora are collections of texts that have been qualitatively validated, according to certain criteria, to be used for the extraction of linguistic data that serve as models of language use. |
Source: Rogobete et al., 2021
What are expert writing corpora?
Most expert corpora are L1 corpora, written in the user’s mother tongue; however, data in certain corpora have to be pre-selected in case the writing is not guaranteed to be “expert” (e.g. written texts by student learners that have received poor grades). While there are several corpora of expert English L1, for low-resource languages such as Romanian, there are limited instruments (Table 1).
 Table 1: Expert corpora – examples
Table 1: Expert corpora – examples
Additionally, expert corpora in L2 writing need to be compiled according to clearly predefined criteria (Fig.1). Nonetheless, the accessibility of such corpora and resources is limited, either because access is licence-based (e.g. COCA) or they overlap with specialised corpora, with only subsets of data being “expert”.
 Fig.1: Criteria for expert corpora in L2
Fig.1: Criteria for expert corpora in L2
Source: Rogobete et al., 2021, full article here
Reference:
Băniceru, C., Tucan, D. “Perceptions About “Good Writing” and “Writing Competences” in Romanian Academic Writing Practices: A Questionnaire Study”. In Chitez, M., Doroholschi, C.I., Kruse, O., Salski, Ł., Tucan, D. (Eds.), University Writing in Central and Eastern Europe: Tradition, Transition, and Innovation, Cham, Springer, 2018, 103-112.
Challenges regarding resource indetification and retrieval
When assessing the linguistic resources to be included in the expert corpus EXPRES, a multitude of challenges emerges:
Language related challenges
At the level of academic text selection a few caveats were identified. From the three types of languages targeted by the study the category of expert writing produced in Romanian L1 revealed a numerical imbalance between the academic writing samples from different fields (see Section 4.3).
Furthermore, in the case of English as L1, the main limitation concerns identifying the appurtenance of the author(s) to a L1 community. Although in ELT literature there are references to L1 versus L2 writing, this is discussed from the perspective of language learning and writing is seen as an indicator of linguistic proficiency, rather than reflecting the reliability of an academic specialised text (see Silva 1993, 1997), on the differences/similarities: L1 vs L2 writing). Since a working definition had to be put forward, in the case of L1 English academic text samples we proposed a possible checklist to be considered. Thus, from the point of view of the text producer(s) the more criteria they comply with the better: affiliation with a university from a country whose sole official language is English, native speaker(s) or equivalent (if Bio/CV/language history available), journal impact factor. We have to deal here with the possibility of a multi-authored text, where the producers’ L1 is different and also consider variation in the linguistic level (Yilmaz & Römer, 2020], as in other cases, “proficiency levels appear to vary a great deal” (Mauranen, 2008).
As concerns English as L2, textual intervention might prove to be an issue. Since professional translation services are but a click away, it may prove a daunting task to determine the extent to which the English academic text belongs to its author(s)’ voice. Moreover, the editorial process of established journals may prompt resorting to amendments to the original voice (suggestions for revision, multiple submissions, professional editing). For further research stages, solutions need to be sought and well thought to mitigate these issues.
Legal aspects
Another challenge we encountered refers to the legal aspects concerning the corpus data: copyright issues. Most of our linguistic sources are online journals that adopt an open-access policy. Many articles published in such journals are distributed under a Creative Commons license that grants copyright permissions and offers a standard set of terms and conditions that licensors may impose. In addition, we encountered another copyright issue regarding subscription-based journals, indexed in international databases (EBSCO, ERIH+, CEEOL etc.). They have all rights reserved, which means we have to obtain the copyright holder’s permission to use their work in our corpus. Asking for individual permission might hamper progress in DACRE – given the communication workload – but, as such articles are valuable for our research, we are considering this approach as well.
Availability
In terms of availability of the resources, the Linguistics field seems to be privileged, while in domains such as IT or even Economics (Fig.2) there are almost no valuable journals that publish in Romanian, considering our main criteria: quality of the publications, indexation and publishing date. One possible solution was to extend the publication date period of the articles, looking for papers written up to 10 years earlier (with no result). Another solution was to search also for books published in Romanian by scholars (with some results, but difficult to download or access the source).
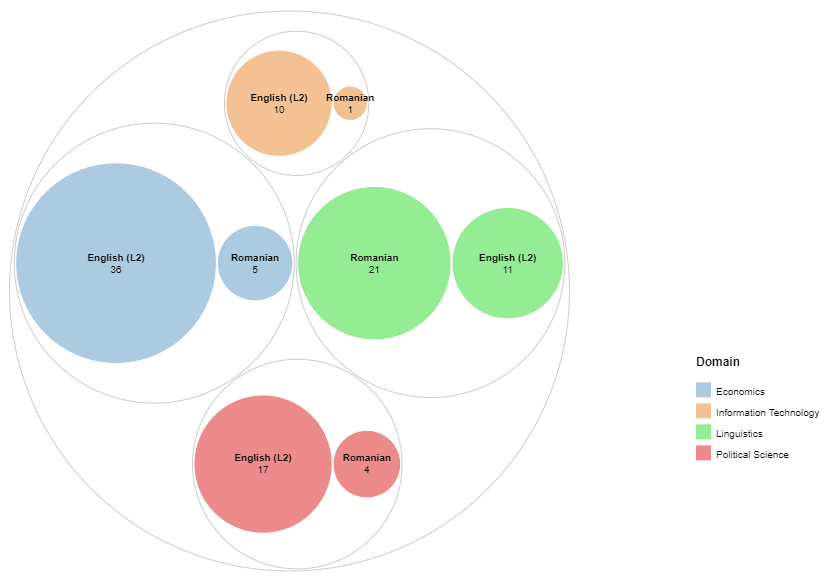 Fig.2: Status of scientific article collection in the EXPRES corpus
Fig.2: Status of scientific article collection in the EXPRES corpus
Multi-authorship
Another challenge regarding articles written in English L2 by Romanian researchers has been the tendency towards multi-authorship, which has been encountered mostly in the IT field: a significant amount of IT articles have been written in collaboration with other (especially foreign) researchers. We have several hypotheses regarding potential causes for multi-authorship: Romanian IT researchers tend to publish articles via conferences, or the collaborations provide more access to international journals. As such, the issue of multi-authorship might affect our data collection process.
Source: Rogobete et al., 2021, full article here
Using automated models
The main challenge in the automatic collection of scientific articles from online libraries is that, even if some platforms allow manual downloading, they may not allow scraping/other computational methods to retrieve documents. Web scraping can be detected from online behaviour (e.g. repetitive patterns, multiple page visits in a short period of time) primarily by machine learning algorithms (Meschenmoser et al, 2020).
In the process of automating the extraction of articles from full journal volumes and issues containing multiple works, processing the documents despite their different formats is challenging. In order to detect each article bound from the pdf documents, the page numbers for each paper are extracted through computational models from the table of contents. It is a tedious task, as the table of contents varies between journals and it is hard to develop an algorithm capable of processing all the different formats of the volumes.
References:
Mauranen, A., Ranta, E. “English as an Academic lingua franca – the ELFA project”, Nordic Journal of English Studies, 7(3), 2008, 199-202.
Meschenmoser, P., Meuschke, N., Hotz, M., Gipp, B. “Scraping scientific web repositories: Challenges and solutions for automated content extraction”, D-Lib Magazine, 22(9/10), 2016.
Silva, T. “Toward an Understanding of the Distinct Nature of L2 Writing: The ESL Research and Its Implications”, TESOL Quarterly, 27(4), 1993, 657-677.
Silva, T. “Differences in ESL and native-English speaker writing: The research and its Implications”. In Severino, C., Guerra, J.C., Butler, J.E. (Eds.), Writing in multicultural settings, New York, Modern Language Association of America, 1997, 209-219.
Yilmaz, S., Römer, U. “A corpus-based exploration of constructions in written academic English as a lingua franca”. In Römer, U., Cortes, V., Friginal, E. (Eds.), Advances in Corpus-based Research on Academic Writing. Effects of discipline, register, and writer expertise, Amsterdam/Philadelphia, John Benjamins, 2020, 59-88.
Tools
(report in internal review process)
By describing, comparing and analyzing data collection barriers, we can now propose a model for expert corpus building in English vs in low-resource languages such as Romanian (Table 2):
 Table 2: Data collection models
Table 2: Data collection models
The preliminary corpus collection stages in DACRE revealed the prevalence of a vicious cycle that affects corpus-based research in low-resource languages: for example, the high degree of challenges in building expert corpora originates in the lack of peer-reviewed publications in the mother tongue and the difficulty to identify expert-level English L2 writings.
Source: Rogobete et al., 2021, full article here
Coding table
Target corpus size
The core of the DACRE project is the linguistic databasis consisting of expert academic writing in the disciplines: Corpus of Expert Writing in Romanian and English (EXPRES). The type of texts selected to represent the category of “expert writing” is the research article (RA). Data is collected from the web and compiled into a comparable (Baker 1996) web-based corpus containing twelve sets if data (twelve sub-corpora) distributed as follows:
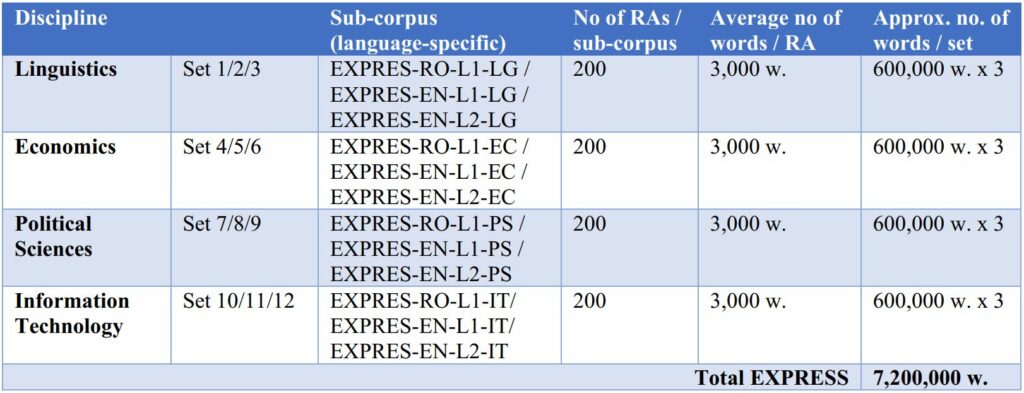 Table 3: EXPRES corpus size (approximate planned size)
Table 3: EXPRES corpus size (approximate planned size)
To ensure the representativeness (Berber-Sardinha 2014) of the texts included in the corpus, clear criteria for selection and inclusion will be evaluated and determined. For example, in the case English L2 data set, texts (i.e. RAs) are selected that are published by Romanian native speakers in English L2 in either national or international publications.
Baker, M. (1996). Corpus-based translation studies: the challenges that lie ahead. In Somers, H. (Ed.), Terminology, LSP and Translation: Studies in Language Engineering in Honour of Juan C. Sager (pp. 175-186). Amsterdam/Philadelphia: John Benjamins Publishing Company.
Corpus construction
From the texts extracted in the first stage of collection, only the texts that corresponded qualitatively to fit the profile of the EXPRESS database were selected and processed for the final version of the corpus. Thus, texts were included that: have a representative length for the respective discipline; they originate from high impact journals; the team of authors represents a single language (for example, only Romanian authors, even in articles with multiple authors, for the Ro dataset); texts that are typical for the discipline (e.g. Linguistics and not Literary Studies).
The texts were processed in .txt format (based on simplified TEI text coding rules) and coded to be uploaded to the corpus access platform, available at: www.expres-corpus.org. Special care was taken to anonymize the data (name, affiliation, etc.) to ensure that the data only serve holistic linguistic research purposes and not individual analysis of scientific articles.
| For an update on the size and typology of the EXPRES corpus, please visit the EXPRES platform at: |  |
References
Baker, M. (1996). Corpus-based translation studies: the challenges that lie ahead. In Somers, H. (Ed.), Terminology, LSP and Translation: Studies in Language Engineering in Honour of Juan C. Sager (pp. 175-186). Amsterdam/Philadelphia: John Benjamins Publishing Company.
Berber Sardinha, T. (2014). 25 years later: Comparing Internet and pre-Internet registers. In Berber Sardinha, T. & Veirano Pinto, M. (Eds.), Multi-Dimensional Analysis, 25 Years on: A Tribute to Douglas Biber (pp. 81-105). Amsterdam/Philadelphia: John Benjamins Publishing Company
Update 1: October 2021
(report in internal review process)
Case study #1: Authorial presence (stance) in novice versus expert writing
In August 2021, a case study was conducted, in order to contribute to the conference presentation given by Dr habil Madalina Chitez in the form of an invited symposium talk. The paper was presented at the CorpusCALL symposium Professional cooperation for DDL and corpus-informed teaching, organized in the frame of the International Conference EUROCALL 2021 – International Conference of the European Association of Computer Assisted Language Learning (Paris, France, virtual). The symposium was hosted by Prof. Reka R. Jablonkai (University of Bath) chair, and Prof. Luciana Forti (University for Foreigners of Perugia) secretary.
More information about the presentation here.
The datasets contained Academic Writing samples from the discipline of Information Technology:

The main outcome of the study was the following:

Case study #2: EXPRES Corpus for A Field-specific Automated Exploratory Study of L2 English Expert Scientific Writing
A case study was presented by Ana-Maria Bucur, Madalina Chitez, Valentina Mureșan, Andreea Dincă and Roxana Rogobete, at the Language Resources and Evaluation Conference (LREC), 13th edition, held in Marseille, France, in June 20-25, 2022. The paper EXPRES Corpus for A Field-specific Automated Exploratory Study of L2 English Expert Scientific Writing is an exploratory study in which the research team tested an automated language assessment model that includes features relevant to the interdisciplinary learning framework of a foreign language: text complexity analysis features, such as syntactic and lexical complexity, and domain-specific academic word lists. We analyzed how these characteristics vary between four disciplinary fields (Economics, IT, Linguistics and Political Acience) in a corpus of L2-English expert academic writing, part of the EXPRES (Corpus of Expert Writing in Romanian and English) corpus. Variation in domain-specific writing is also analyzed in groups of linguistic features drawn from higher visibility (Hv) versus lower visibility (Lv) journals.
The main result of the study is the following:
After applying the formulas detecting the degree of lexical sophistication, lexical variation and syntactic complexity, significant differences between disciplines were identified: mainly, research articles in Lv journals have higher lexical complexity but less syntactic complexity than Hv journal articles, while academic vocabulary has been shown to display discipline-specific variation.
More information about the presentation here.
Study case #3: Challenges in compiling expert corpora for academic writing support
Roxana Rogobete, Mădălina Chitez, Valentina Mureșan, Bogdan Damian, Adrian Duciuc, Claudiu Gherasim and Ana-Maria Bucur presented the paper Challenges in compiling expert corpora for academic writing support at the 11th edition of The Future of Education International Conference (Florence, Italy, virtual edition, July 1-2, 2021). The authors analyzed the challenges encountered in the compilation of expert-writing corpora for discipline-specific academic writing, for Romanian as a mother tongue and English as a secondary language. Among these, we list: lack of consistency of publications, availability of articles, lack of resources for certain samples in the corpus, co-authorship, legal aspects (such as copyright).
The main result of the study is the following:
By describing, comparing, and analysing the challenges encountered in creating a corpus of expert academic writing, we have proposed a contrastive model of approaching data for an expert corpus in English versus approaching data for corpora in less-studied languages, like the Romanian language.
More information about the presentation here.
Study case #4: Phraseology in Romanian Academic Writing: Corpus Based Explorations into Field-Specific Multiword Units
Another study with applicability for academic writing in Romanian, completed in 2022, is the chapter published by Valentina Mureșan, Roxana Rogobete, Ana-Maria Bucur, Mădălina Chitez and Andreea Dincă in the collective volume edited by Madalina Chitez, Anca Dinu, Liviu Dinu and Mihnea Dobre, Recent Advances in Digital Humanities, published by Peter Lang in Berlin. The chapter proposes a computational linguistics approach to the extraction and analysis of discipline-specific multiword units using academic writing corpora. The method was tested on the same two corpora, ROGER (novice academic writing) and EXPRES (expert academic writing).
The main result of the study is the following:
We identified co-occurring words, collocations, n-grams, which can be further processed to build academic word lists. These lists can be consulted by researchers during the process of writing academic texts, but they can also be used to detect possible inaccuracies, given the lack of resources on academic writing in Romania.
More about volume here.
Study case #5: How to write good academic papers: using the EXPRES corpus to extract expert writing linguistic patterns
Another case study was prepared for the 12th edition of the international conference The Future of Education, organized in Florence from June 30 to July 1, 2022. Madalina Chitez, Valentina Carina Mureșan and Roxana Rogobete presented the paper How to write good academic papers: using the EXPRES corpus to extract expert writing linguistic patterns, which exemplifies and highlights the potential of using expert corpora to improve academic writing in different fields. The study demonstrates how academic writing support is becoming a vital component of the acquisition and dissemination of disciplinary expertise. At the same time, the EXPRES corpus was presented, with its dedicated data query platform, which allows the search and extraction of the desired linguistic elements (words, phrases, models, n-grams) and the statistical visualization of the data.
The main result of the study is the following:
We used corpus-specific research methods to extract linguistic patterns that can be useful in the process of writing academic papers. The extracted patterns are distributed into discipline-specific characteristics and general features of academic writing. At the same time, as EXPRES is a bilingual (Romanian-English) corpus, all linguistic results also have language-specific distributions and descriptions.
More information about the presentation here.
Study case #6: Using bilingual novice and expert corpora to teach academic writing at the university: The case of ROGER and EXPRES
The DACRE research team conducted an applied comparative study that was presented at the 15th Teaching and Language Corpora (TaLC) Conference, organized by the University of Limerick, Ireland, from 13-16 July 2022. Andreea Dinca, Madalina Chitez, Loredana Bercuci, Alexandru Oravitan and Roxana Rogobete presented the paper Using bilingual novice and expert corpora to teach academic writing at the university: The case of ROGER and EXPRES. Based on two bilingual corpora and platforms - ROGER (elaborated within a previously completed project, Academic genres at the crossroads of tradition and internationalization: Corpus-based interlanguage research on genre use in student writing at Romanian universities) - respectively EXPRES (elaborated within the DACRE project), we presented the main functionalities of the two platforms and introduced some research-based teaching models that use the mentioned corpora, to facilitate the learning of academic writing.
The main result of the study is the following:
We presented video tutorials and sample texts uploaded to the platforms created with the aim of popularizing the use of authentic data (native and L2 English, novice and expert) for the design and implementation of corpus-based academic writing teaching activities.
More about the presentation here.
Study case #7: Academic Word Lists in English and Romanian: a corpus-based contrastive analysis
Another case study approaching academic writing support tools was presented by Roxana Rogobete, Valentina Mureșan and Mădălina Chitez, at the tenth edition of the International Colloquium Communication and Culture in European Romania (CICCRE), with the theme Identity - Diversity, organized by the Western University of Timișoara in online format during June 10-11, 2022. In the communication entitled Lists of academic words in Romanian and English: a contrastive analysis based on the corpus, the authors found that, for multiple reasons, the space Romanian does not abound in studies related to academic writing in Romanian - few researches deal with a panorama of writing practices in the university environment, but even fewer deal, differentiated, with the vocabulary or writing principles specific to certain disciplines. In this context, the Romanian "scientific production" is extremely varied at the discursive level, both because of the fact that there are no uniform skills at the level of the curriculum aimed at university writing, and because of the heterogeneity of the rules of writing and the conditions of publication imposed by the journals specialized Romanian.
The main result of the study is the following:
The aim of this study was to analyze the relevance of academic word lists (Academic Word List) for native academic writing, bringing into discussion examples and methodologies from the sphere of the English language, in which case tools such as the one proposed by Avery Coxhead at the end of the 90s have proven their effectiveness. The applied dimension of the paper is based on the analysis of the expert, bilingual corpus of scientific articles - EXPRES - compiled within the DACRE project. The aim of the study is to propose and exemplify the possibility of building such a glossary starting from the practice of writing, by examining some results provided by corpus linguistic tools, such as N-Grams or concordance lines.
More about the presentation here.
The EXPRES platform (it was renamed to reflect the corpus name but the DACRE project is explicitly mentioned in the platform) has been completed and is available to the general public at the end of the DACRE project (December 2022).
The access address is: www.expres-corpus.org.
HOME: Home page of the platform EXPRES
The functionalities of the platform are:
Primary functionality: EXPRESS bilingual corpus query interface; access is based on login with a valid account, to avoid spam.
The frontend interface offers registered users the ability to search for specific keywords and refine the results by applying filters. Current features of the platform include term and phrase search, distribution of n-grams in the corpus, and statistical visualizations for performed queries. After entering a term/phrase in the search window, the user can filter the available texts by: (i) language (English L1, English L2, Romanian); (ii) field (4 fields: Linguistics, Political Sciences, Economic Sciences, IT); (iii) type of access to the text: open or restricted. A number of solutions have been implemented to improve the response times of computational procedures handling large amounts of data.

SEARCH: The EXPRES corpus search interface
Secondary functionalities of an informative nature: The main page ("Home") contains information about the corpus ("About"), corpus annotation, user tutorials ("Tutorials", section under construction) and project publications ("Research"). The "Statistics" page also provides visitors with general, quantitative data about the corpus.

ABOUT: General information about the EXPRES corpus
CORPUS DOCUMENTATION: Information on corpus processing
Advanced backend functionalities for the admin account: The backend interface available to authenticated administrators (DACRE research team) provides the digital tools for managing the texts stored in the database and associated metadata and it also provides an extensive statistics mechanism covering text typology and data characteristics (words, characters, languages, domains and grams).
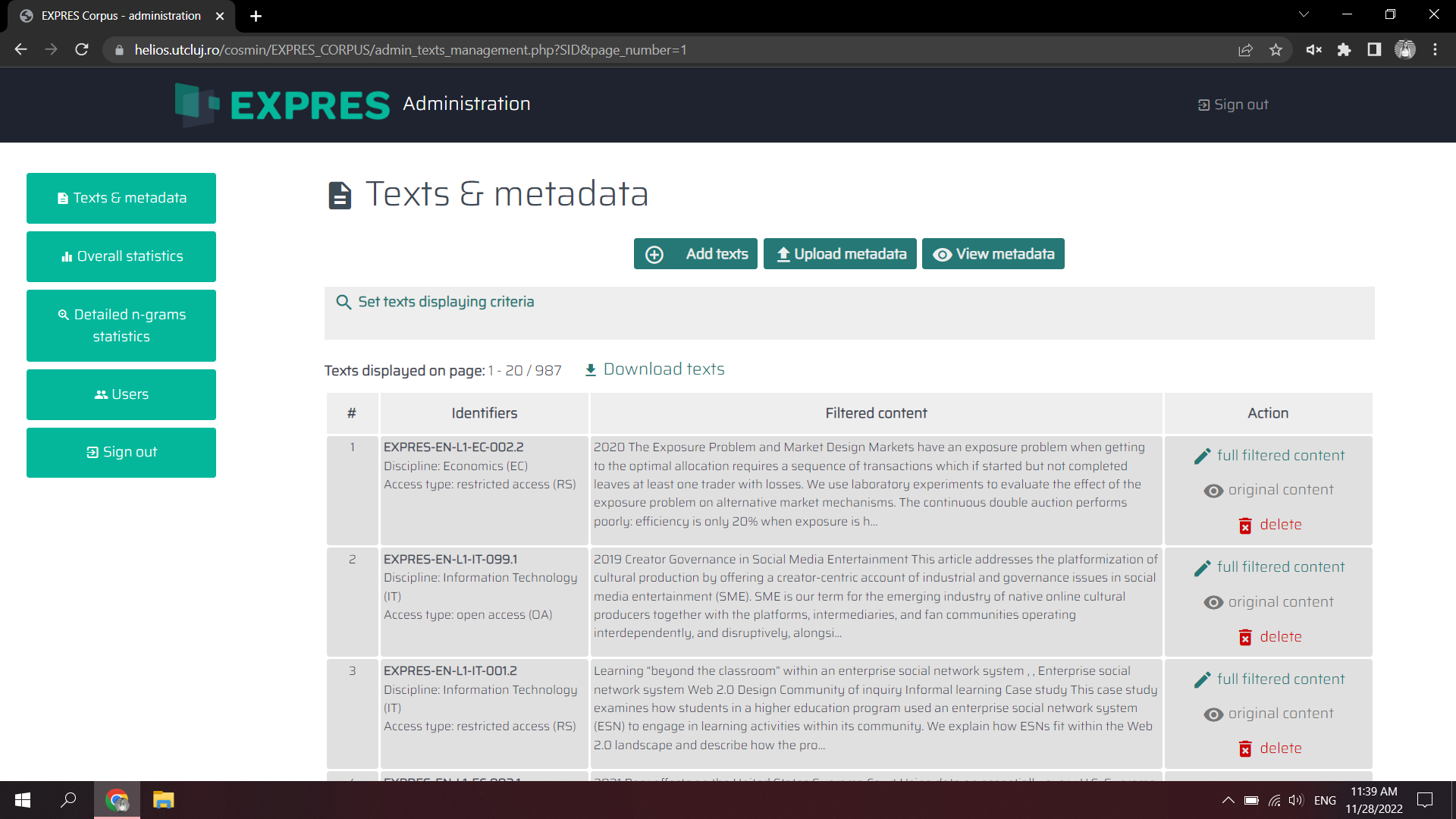
BACKEND: Metadata administration page for the EXPRES corpus