Ce este scrierea de tip expert?
Cum își dobândesc/îmbunătățesc cercetătorii abilitățile de scriere academică? În general, există un decalaj teoretic în ceea ce privește identificarea tiparelor lingvistice în cadrul textelor academice dintr-un anumit domeniu de specialitate. Tipologiile discursive coagulate de instituțiile românești de învățământ superior, de exemplu, sunt mult prea puțin cercetate (Baniceru & Tucan, 2018), în ceea ce privește atât limba română (L1), cât și limba engleză (L2), mai ales dintr-o perspectivă a analizelor cantitative. La fel ca în cazul altor limbi, pentru contextul românesc, există puține practici de scriere academică bazate pe cercetări riguroase: universitarii compensează acest lucru prin utilizarea intuitivă a unor modele oferite de manuale/lucrări de cercetare. În mod sistematic și la o scară mai largă, o astfel de practică poate fi sprijinită și completată de utilizarea unor corpusuri de tip expert.
| În sens larg, corpusurile expert sunt colecții de texte care au fost validate din punct de vedere calitativ, în acord cu diferite criterii, astfel încât pot fi utilizate pentru extragerea datelor lingvistice. Acestea pot servi drept model al uzului limbii. |
Sursa: Rogobete et al., 2021, articol complet aici
Ce sunt corpusurile de tip expert?
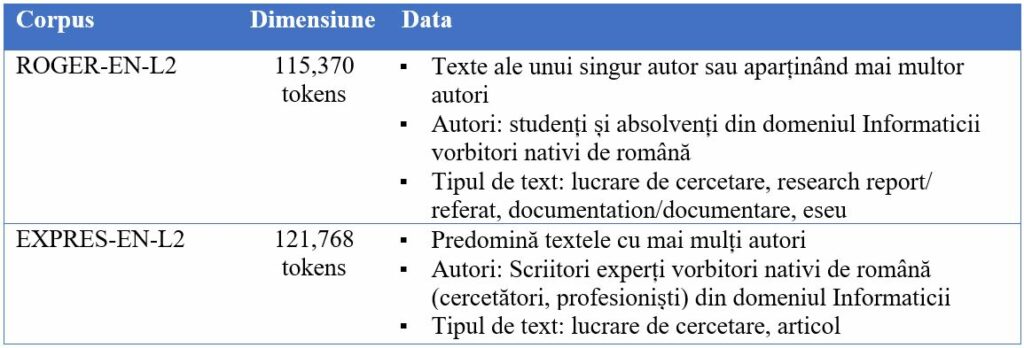
Majoritatea corpusurilor expert sunt corpusuri L1, scrise în limba maternă a utilizatorilor; cu toate acestea, datele din anumite corpusuri trebuie să fie selectate anterior în caz că nu se poate demonstra că scrierea este de tip expert (de exemplu, textele scrise de studenți care sunt notați cu un punctaj mic). În timp ce există câteva corpusuri de limba engleză L1 de tip expert, pentru limbile cu mai puține resurse, precum româna, instrumentele de lucru sunt limitate (Tabelul 1).

Tabel 1: Exemple de corpusuri expert
În plus, corpusurile expert pentru scrierea în L2 trebuie să fie compilate în funcție de criterii predefinite clare (Fig.1). Cu toate acestea, accesibilitatea acestui tip de corpusuri și resurse este limitată, fie pentru că accesul este permis exclusiv membrilor autorizați (de exemplu, COCA), fie deoarece există o suprapunere cu corpusuri specializate, care au doar unele elemente de tip expert.
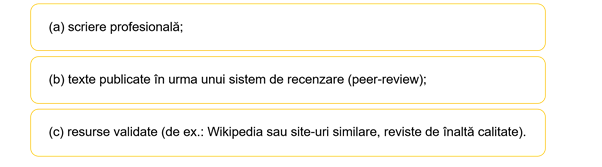 Fig.1: Criterii pentru compilarea corpusurilor expert de tip L2
Fig.1: Criterii pentru compilarea corpusurilor expert de tip L2
Sursa: Rogobete et al., 2021, articol complet aici
Referințe:
Băniceru, C., Tucan, D. “Perceptions About “Good Writing” and “Writing Competences” in Romanian Academic Writing Practices: A Questionnaire Study”. In Chitez, M., Doroholschi, C.I., Kruse, O., Salski, Ł., Tucan, D. (Eds.), University Writing in Central and Eastern Europe: Tradition, Transition, and Innovation, Cham, Springer, 2018, 103-112.
Provocări referitoare la identificarea resurselor și colectarea datelor
Există o multitudine de provocări în momentul în care ne propunem să realizăm evaluarea nivelului lingvistic al resurselor ce vor fi incluse în corpusul expert EXPRES:
Provocări legate de limbă
La nivelul selecției textelor academice au fost identificate câteva limitări. Din cele trei tipuri de limbi vizate de studiu, categoria scrierii de tip expert în limba română L1 a expus un dezechilibru numeric între eșantioanele de scriere academică din diferite domenii (vezi secțiunea 4.3).
În plus, în cazul limbii engleze ca limbă maternă (L1), principala limitare se referă la identificarea apartenenței autorului (autorilor) la o comunitate L1. Deși în literatura ELT există referințe la scrierea L1 versus L2, acest aspect este discutat din perspectiva învățării limbii iar scrierea este văzută ca un indicator al competenței lingvistice, mai degrabă decât să reflecte fiabilitatea unui text academic specializat (vezi Silva 1993, 1997, despre diferențe/asemănări: scrierea în limba engleză ca limbă maternă vs scrierea în limba engleză ca limbă secundară). Având în vedere că a trebuit prezentată o definiție de lucru, în cazul eșantioanelor de texte academice scrise în limba engleză ca limbă maternă am propus o listă posibilă de verificare care trebuie luată în considerare. Astfel, din punctul de vedere al producătorului (producătorilor) de text, cu cât respectă mai multe criterii, cu atât mai bine: afilierea la o universitate dintr-o țară a cărei singură limbă oficială este engleza, vorbitor(i) nativ(i) sau echivalent (în funcție de disponibilitatea biografiei/CV-ului/istoricului limbii), factorul de impact al revistei. Trebuie să ne ocupăm în acest caz de posibilitatea unui text cu autori multipli, în care limba maternă a producătorilor este diferită și, de asemenea, să luăm în considerare variația nivelului lingvistic (Yilmaz & Römer, 2020), ca și în alte cazuri, „nivelurile de competență par să varieze foarte mult” (Mauranen, 2008).
În ceea ce privește limba engleză ca limbă secundară, intervenția textuală s-ar putea dovedi a fi o problemă. Deoarece serviciile profesionale de traducere sunt doar la un click distanță, determinarea măsurii în care textul academic în limba engleză aparține vocii autorului (autorilor) poate reprezenta o sarcină descurajantă. Mai mult, procesul editorial al revistelor consacrate poate determina recurgerea la modificări ale vocii originale (sugestii de revizuire, depuneri multiple, editare profesională). Pentru etapele ulterioare ale cercetării, trebuie căutate soluții bine gândite pentru a diminua aceste probleme.
Aspecte legale
O altă provocare pe care am întâlnit-o se referă la aspectele legale privind datele corpusului: drepturile de autor. Majoritatea surselor noastre lingvistice sunt reviste online care adoptă o politică de acces liber. Multe articole publicate în astfel de reviste sunt distribuite sub o licență Creative Commons care acordă permisiuni de copyright și oferă un set standard de termeni și condiții pe care licențiatorii îl pot impune. În plus, am întâlnit o altă problemă privind drepturile de autor ce vizează revistele pe bază de abonament, indexate în baze de date internaționale (EBSCO, ERIH+, CEEOL etc.). Acestea au toate drepturile rezervate, ceea ce înseamnă că trebuie să obținem permisiunea deținătorului drepturilor de autor pentru integra articolele în corpusul nostru. Solicitarea permisiunii individuale ar putea împiedica progresul DACRE – având în vedere volumul de lucru al comunicării – dar, întrucât astfel de articole sunt valoroase pentru cercetarea noastră, avem în vedere și această abordare.
Disponibilitate
În ceea ce privește disponibilitatea resurselor, domeniul lingvistic pare a fi privilegiat, în timp ce în domenii precum IT sau științe economice (Fig.2) publicațiile valoroase în limba română sunt aproape inexistente, dacă ținem cont de criteriile principale adoptate pentru corpus: calitatea lucrărilor, indexarea și data publicării. O soluție a fost extinderea intervalului de publicare pentru articolele căutate, căutând texte scrise până în urmă cu 10 ani (fără rezultate notabile). O altă metodă a presupus includerea în căutare a cărților publicate în limba română de către cercetători (cu rezultate modeste, având în vedere dificultatea de a descărca sau accesa volumele).
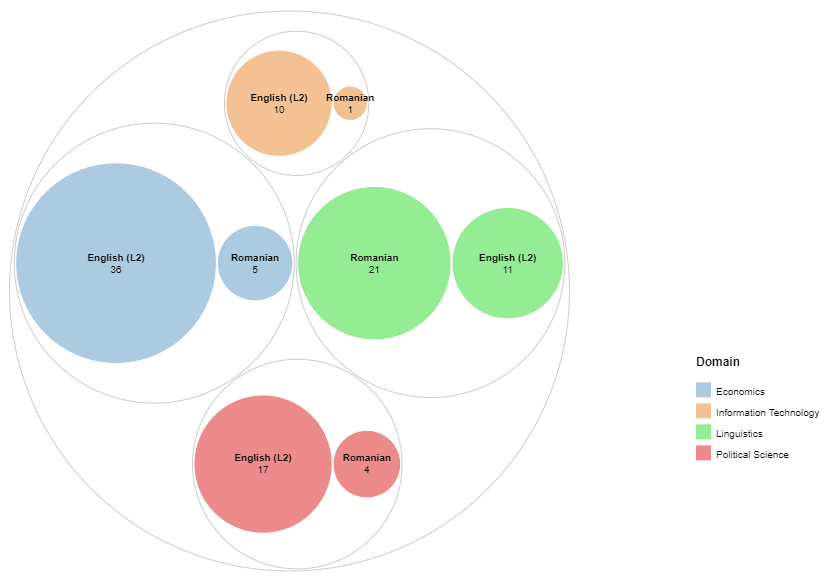 Fig.2: Statusul colectării articolelor științifice în corpusul EXPRES
Fig.2: Statusul colectării articolelor științifice în corpusul EXPRES
Coautorat
O altă provocare în ceea ce privește articolele scrise în limba engleză L2 de către cercetătorii români a fost reprezentată de frecvența coautoratului, întâlnit de cele mai multe ori în domeniul IT: un număr semnificativ de articole a fost scris de autorii români în colaborare cu alți cercetători (în special din străinătate). Putem emite câteva ipoteze referitoare la potențialele motivații ale coautoratului: cercetătorii români din domeniul IT au tendința de a publica articole prin intermediul conferințelor (conference proceedings), ori aceste colaborări oferă mai mult acces la publicații de talie internațională. Ca atare, chestiunea coautoratului poate influența procesul nostru de colectare a datelor.
Sursa: Rogobete et al., 2021, articol complet aici
Utilizarea modelelor automate
Principala provocare în colectarea automată a articolelor științifice de pe platforme online este reprezentată de faptul că, deși unele site-uri permit descărcarea manuală, este posibil ca acestea să nu permită scraping de date sau alte metode computaționale pentru a accesa documentele. Web scrapingul poate fi detectat în mediul online (de exemplu, din cauza schemelor repetitive, a vizitelor multiple pe pagină într-o perioadă scurtă de timp), în primul rând prin algoritmi de învățare automată (Meschenmoser et al, 2020).
În procesul de extragere automată a articolelor din volume complete ale publicațiilor ce conțin numeroase lucrări, dificilă este și procesarea documentelor, având în vedere diferitele formate în care se prezintă. Pentru a detecta și separa fiecare articol dintr-un fișier pdf extins, numerele paginilor pentru fiecare articol sunt extrase utilizând modele computaționale aplicate cuprinsului unui volum. Este o sarcină anostă, de vreme ce formatul cuprinsului este diferit de la o publicație la alta și dezvoltarea unui algoritm capabil să proceseze toate aceste modele este anevoioasă.
Referințe:
Mauranen, A., Ranta, E. “English as an Academic lingua franca – the ELFA project”, Nordic Journal of English Studies, 7(3), 2008, 199-202.
Meschenmoser, P., Meuschke, N., Hotz, M., Gipp, B. “Scraping scientific web repositories: Challenges and solutions for automated content extraction”, D-Lib Magazine, 22(9/10), 2016.
Silva, T. “Toward an Understanding of the Distinct Nature of L2 Writing: The ESL Research and Its Implications”, TESOL Quarterly, 27(4), 1993, 657-677.
Silva, T. “Differences in ESL and native-English speaker writing: The research and its Implications”. In Severino, C., Guerra, J.C., Butler, J.E. (Eds.), Writing in multicultural settings, New York, Modern Language Association of America, 1997, 209-219.
Yilmaz, S., Römer, U. “A corpus-based exploration of constructions in written academic English as a lingua franca”. In Römer, U., Cortes, V., Friginal, E. (Eds.), Advances in Corpus-based Research on Academic Writing. Effects of discipline, register, and writer expertise, Amsterdam/Philadelphia, John Benjamins, 2020, 59-88.
Descriind, comparând și analizând barierele din setul de date, putem propune un model pentru crearea de corpusuri expert în engleză comparativ cu limbile cu resurse limitate, precum româna (Tabelul 2):
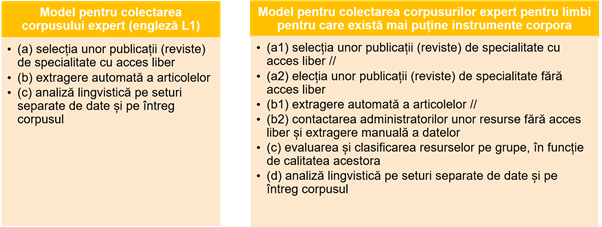 Tabel 2: Modele pentru colectarea datelor
Tabel 2: Modele pentru colectarea datelor
Etapele preliminare ale compunerii corpusului DACRE au expus prevalența unui cerc vicios care afectează analiza bazată pe corpus în cazul limbilor cu resurse limitate: de exemplu, numeroasele provocări în întocmirea corpusurilor au drept sursă lipsa de publicații evaluate de referenți știinfici în limba maternă și dificultatea de a identifica scrieri în engleză L2 la nivel expert.
Sursa: Rogobete et al., 2021, articol complet aici
Tabel codare
Obiectivul și dimensiunea corpusului
Nucleul proiectului DACRE constă într-o bază de date lingvistică centrată pe scrierea academică specifică disciplinei: Corpus of Expert Writing in Romanian and English (EXPRES). Tipul de text selectat pentru a reprezenta această categorie de „scriere expertă” este lucrarea de cercetare. Datele sunt colectate de pe internet și integrate într-un corpus web de tip comparabil (Baker 1996) care conține douăsprezece seturi de date (douăsprezece sub-corpusuri) distribuite după cum urmează:
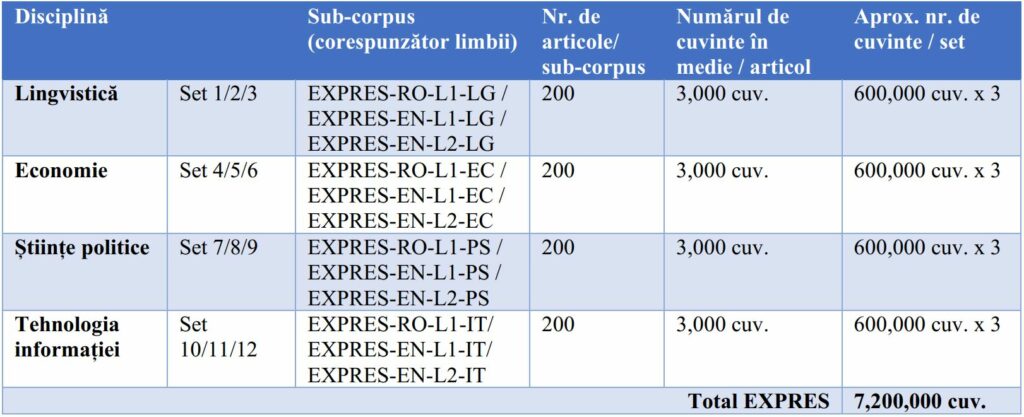 Tabelul 3: Dimensiunea corpusului EXPRES (dimensiunea planificată aproximativă)
Tabelul 3: Dimensiunea corpusului EXPRES (dimensiunea planificată aproximativă)
Pentru a asigura caracterul reprezentativ (Berber-Sardinha 2014) al textelor incluse în corpus, criterii clare de selecționare și includere vor fi evaluate și determinate. De exemplu, în cazul setului Engleză L2, sunt selectate din publicații naționale și internaționale texte scrise în engleză de vorbitori nativi de limba română.
Baker, M. (1996). Corpus-based translation studies: the challenges that lie ahead. In Somers, H. (Ed.), Terminology, LSP and Translation: Studies in Language Engineering in Honour of Juan C. Sager (pp. 175-186). Amsterdam/Philadelphia: John Benjamins Publishing Company.
Realizarea corpusului
Din textele extrase în prima etapă de colectare , au fost selectate și procesate pentru varianta finală de corpus doar textele care corespundeau din punct de vedere calitativ pentru a se încadra în profilul bazei de date EXPRES. Astfel, au fost incluse textele care: au o lungime reprezentativă pentru disciplina respectivă; provin din reviste bine cotate; echipa de autori reprezintă o singură limbă (de exemplu, numai autori români, chiar și în articole cu autori multipli, pentru setul de date Ro); texte care sunt tipice pentru disciplina respectivă (de exemplu, Lingvistică și nu Studii Literare).
Textele au fost procesate în format .txt (bazat pe norme de codare text TEI simplificate) si codate pentru a fi urcate în platforma de accesare corpus, disponibilă la: www.expres-corpus.org. A fost acordată o atenție specială anonimizării datelor (nume, afiliere etc.) pentru a fi siguri că datele deservesc exclusiv scopuri de cercetare holistică în domeniul lingvistic și nu de analiză individuală de articole științifice.
| Pentru o actualizare cu privire la dimensiunea și tipologia corpusului EXPRESS, vă rugăm să vizitați platforma EXPRESS la: |  |
Referințe:
Baker, M. (1996). Corpus-based translation studies: the challenges that lie ahead. In Somers, H. (Ed.), Terminology, LSP and Translation: Studies in Language Engineering in Honour of Juan C. Sager (pp. 175-186). Amsterdam/Philadelphia: John Benjamins Publishing Company.
Berber Sardinha, T. (2014). 25 years later: Comparing Internet and pre-Internet registers. In Berber Sardinha, T. & Veirano Pinto, M. (Eds.), Multi-Dimensional Analysis, 25 Years on: A Tribute to Douglas Biber (pp. 81-105). Amsterdam/Philadelphia: John Benjamins Publishing Company
Update 1: Octombrie 2021
(raport aflat în proces de revizuire internă)
Studiu de caz #1: Prezența autorului (instanțe) în scriere de tip expert vs scriere a novicilor
În august 2021, a fost efectuat un studiu de caz pentru a contribui la prezentarea susținută de Dr habil Madalina Chitez în cadrul conferinței plenare la care a fost invitată. Lucrarea a fost prezentată la simpozionul CorpusCALL Professional cooperation for DDL and corpus-informed teaching, organizat în cadrul Conferinței Internaționale EUROCALL 2021 – International Conference of the European Association of Computer Assisted Language Learning (Paris, Franța, virtual). Simpozionul a fost organizat de președintele Prof. Reka R. Jablonkai (Universitatea din Bath) și secretarul Luciana Forti (University for Foreigners din Perugia).
Mai multe informații despre prezentare aici.
Seturile de date conținând mostre de Scriere Academică aferente disciplinei Tehnologia Informației:
Principalul rezultat al studiului este următorul:

Studiu de caz #2: EXPRES Corpus for A Field-specific Automated Exploratory Study of L2 English Expert Scientific Writing
Un studiu de caz a fost prezentat de Ana-Maria Bucur, Madalina Chitez, Valentina Mureșan, Andreea Dincă și Roxana Rogobete, la conferința Language Resources and Evaluation Conference (LREC), ediția a 13-a, desfășurată la Marsilia, Franța, în perioada 20-25 iunie 2022. Lucrarea EXPRES Corpus for A Field-specific Automated Exploratory Study of L2 English Expert Scientific Writing reprezintă un studiu exploratoriu în care echipa de cercetare a testat un model automat de evaluare lingvistică, ce include caracteristici relevante pentru cadrul interdisciplinar al învățării unei limbi străine: caracteristicile de analiză a complexității textului, cum ar fi complexitatea sintactică și lexicală, și listele de cuvinte academice specifice domeniului. Am analizat modul în care aceste caracteristici variază între patru domenii disciplinare (economie, IT, lingvistică și științe politice) într-un corpus de scriere științifică de specialitate L2-engleză, parte a corpusului EXPRES (Corpus of Expert Writing in Romanian and English). Variația în scrierea specifică domeniului este, de asemenea, analizată în grupuri de caracteristici lingvistice extrase din reviste cu vizibilitate mai mare (Hv) față de cele cu vizibilitate mai mică (Lv).
Principalul rezultat al studiului este următorul:
După aplicarea formulelor care depistează gradul de sofisticare lexicală, variație lexicală și complexitate sintactică, au fost identificate diferențe semnificative între discipline: în principal, articolele de cercetare din revistele Lv au o complexitate lexicală mai mare, dar o complexitate sintactică mai mică decât articolele din revistele Hv, în timp ce vocabularul academic s-a dovedit a avea o variație specifică disciplinei.
Mai multe informații despre prezentare aici.
Studiu de caz #3: Challenges in compiling expert corpora for academic writing support
Roxana Rogobete, Mădălina Chitez, Valentina Mureșan, Bogdan Damian, Adrian Duciuc, Claudiu Gherasim și Ana-Maria Bucur au prezentat comunicarea Challenges in compiling expert corpora for academic writing support (Provocări întâmpinate în alcătuirea unui corpus de tip expert pentru susținerea scrierii academice), la cea de-a 11-a ediție a Conferinței Internaționale The Future of Education (Florența, Italia, ediție virtuală, 1-2 iulie 2021). Autorii au analizat provocările întâmpinate în alcătuirea corpusurilor de tip expert pentru scrierea academică specifică disciplinei, pentru limba română ca limbă maternă și limba engleză ca limbă secundară. Dintre acestea, enumerăm: lipsa de consecvență a publicațiilor, disponibilitatea articolelor, lipsa de resurse pentru anumite eșantioane ale corpusului, prezența co-autoratului, aspectele legale (cum ar fi drepturile de autor).
Principalul rezultat al studiului este următorul:
Prin descrierea, compararea și analiza provocărilor întâmpinate în crearea unui corpus de scriere academică de tip expert, am propus un model contrastiv de abordare a datelor pentru un corpus de tip expert în limba engleză versus abordare a datelor pentru corpus-uri în limbile mai puțin studiate, cum este limba română.
Studiu de caz #4: Phraseology in Romanian Academic Writing: Corpus Based Explorations into Field-Specific Multiword Units
Un alt studiu cu aplicabilitate pentru scrierea academică în limba română, finalizat în 2022, reprezintă capitolul publicat de Valentina Mureșan, Roxana Rogobete, Ana-Maria Bucur, Mădălina Chitez și Andreea Dincă în volumul colectiv editat de Madalina Chitez, Anca Dinu, Liviu Dinu și Mihnea Dobre, Recent Advances in Digital Humanities, apărut la editura Peter Lang din Berlin. Capitolul propune o abordare de lingvistică computațională pentru extragerea și analiza unităților multicuvânt specifice unei discipline folosind corpusuri de scriere academică. Metoda a fost testată pe aceleași două corpusuri, ROGER (scriere academică de tip novice) și EXPRES (scriere academică de tip expert).
Principalul rezultat al studiului este următorul:
Am identificat cuvinte co-ocurente, colocații, n-grame, care pot fi prelucrate ulterior pentru a construi liste de cuvinte academice. Aceste liste pot fi consultate de către cercetători în timpul procesului de redactare a textelor academice, dar pot fi, de asemenea, utilizate pentru a detecta eventualele inexactități, având în vedere lipsa de resurse privind scrierea academică din România.
Mai multe despre volum aici.
Studiu de caz #5: How to write good academic papers: using the EXPRES corpus to extract expert writing linguistic patterns
Un alt studiu de caz a fost comunicat la a 12-a ediție a conferinței internaționale The Future of Education, organizată la Florența în perioada 30 iunie – 1 iulie 2022. Madalina Chitez, Valentina Carina Mureșan și Roxana Rogobete au prezentat lucrarea How to write good academic papers: using the EXPRES corpus to extract expert writing linguistic patterns, care exemplifică și evidențiază potențialul utilizării corpusurilor de tip expert pentru îmbunătățirea scrierii academice în diferite domenii. Studiul a demonstrat cum suportul pentru scrierea academică se transformă într-o componentă vitală a proceselor de achiziție și diseminare a expertizei disciplinare. A fost prezentat, totodată, corpusul EXPRES, ce dispune de o platformă dedicată de interogare a datelor, care permite căutarea și extragerea elementelor lingvistice dorite (cuvinte, fraze, modele, n-grame) și vizualizarea statistică a datelor.
Principalul rezultat al studiului este următorul:
Am utilizat metode de cercetare specifice corpusului pentru a extrage modele lingvistice care pot fi utile în procesul de redactare a lucrărilor academice. Tiparele extrase sunt distribuite în caracteristici specifice unei discipline și trăsături generale ale scrierilor academice. În același timp, întrucât EXPRES este un corpus bilingv (română-engleză), toate rezultatele lingvistice au, de asemenea, distribuții și descrieri specifice fiecărei limbi.
Mai multe informații despre prezentare aici.
Studiu de caz #6: Using bilingual novice and expert corpora to teach academic writing at the university: The case of ROGER and EXPRES
Echipa de cercetare DACRE a realizat un studiu comparativ aplicat care a fost prezentat la cea de-a 15-a ediție a Teaching and Language Corpora (TaLC) Conference, organizată de Universitatea din Limerick, Irlanda, în perioada 13-16 iulie 2022. Andreea Dinca, Madalina Chitez, Loredana Bercuci, Alexandru Oravitan și Roxana Rogobete au prezentat lucrarea Using bilingual novice and expert corpora to teach academic writing at the university: The case of ROGER and EXPRES. Bazându-ne pe două corpusuri bilingve și platforme - ROGER (elaborat în cadrul unui proiect finalizat anterior, Academic genres at the crossroads of tradition and internationalization: Corpus-based interlanguage research on genre use in student writing at Romanian universities) - respectiv EXPRES (elaborat în cadrul proiectului DACRE), am prezentat principalele funcționalități ale celor două platforme și am introdus câteva modele de predare bazate pe cercetare care utilizează corpusurile menționate, pentru a facilita învățarea scrisului academic.
Principalul rezultat al studiului este următorul:
Am prezentat tutoriale video și mostre de texte încărcate pe platformele create, cu scopul de a populariza utilizarea datelor autentice (limba maternă și limba engleză L2, novice și expert) pentru proiectarea și implementarea activităților de predare a scrierii academice bazate pe corpusuri.
Mai multe despre prezentare aici.
Studiu de caz #7: Liste de cuvinte academice în limbile română și engleză: o analiză contrastivă bazată pe corpus
Un alt studiu de caz care face referire la crearea de instrumente suport a fost prezentat de Roxana Rogobete, Valentina Mureșan și Mădălina Chitez, la cea de-a zecea ediție a Colocviului Internaţional Comunicare şi cultură în Romania europeană (CICCRE), cu tema Identitate – Diversitate, organizată de Universitatea de Vest din Timișoara în format online în perioada 10-11 iunie 2022. În comunicarea intitulată Liste de cuvinte academice în limbile română și engleză: o analiză contrastivă bazată pe corpus, autoarele au constatat că, din multiple motive, spațiul românesc nu abundă în studii referitoare la scrierea academică în limba română – puține cercetări se ocupă de o panoramă a practicilor de scriere în mediul universitar, dar și mai puține se ocupă, diferențiat, de vocabularul sau principiile de redactare specifice unor discipline. În acest context, „producția științifică” românească este extrem de variată la nivel discursiv, atât din cauza faptului că nu există deprinderi unitare la nivelul curriculumului ce vizează scrisul universitar, cât și din pricina eterogenității normelor de redactare și a condițiilor de publicare impuse de revistele românești de specialitate.
Principalul rezultat al studiului este următorul:
Scopul acestui studiu a fost de a analiza relevanța unor liste de cuvinte academice (Academic Word List) pentru scrierea academică autohtonă, aducând în discuție exemple și metodologii din sfera limbii engleze, în cazul căreia instrumente precum cel propus de Avery Coxhead la finalul anilor ’90 și-au demonstrat eficiența. Dimensiunea aplicativă a lucrării se bazează pe analiza corpusului expert, bilingv, de articole științifice – EXPRES – compilat în cadrul proiectului DACRE. Miza studiului este de a propune și exemplifica posibilitatea construirii unui astfel de glosar pornind de la practica scriiturii, prin examinarea unor rezultate oferite de instrumentele lingvisticii de corpus, precum N-Grams sau linii de concordanță.
Mai multe despre prezentare aici.
Platforma EXPRES (a fost renumită pentru a reflecta numele corpusului dar proiectul DACRE este menționat explicit în platformă) a fost finalizată și este disponibilă publicului larg la finalul proiectului DACRE (decembrie 2022).
Adresa de accesare este: www.expres-corpus.org.
HOME: Pagina principală a platformei EXPRES
Funcționalitățile platformei sunt:
Funcționalitate primară: interfața de interogare a corpusul bilingv EXPRES; accesul se face pe bază de login cu cont valid, pentru evitarea acțiunilor de tip spam.
Interfața frontend oferă utilizatorilor înregistrați posibilitatea de a căuta anumite cuvinte-cheie și de a rafina rezultatele obținute prin aplicarea unor filtre. Caracteristicile actuale ale platformei includ căutarea de termeni și fraze, distribuția n-gramelor în corpus și vizualizări statistice pentru interogările efectuate. După introducerea unui termen/unei fraze în fereastra de căutare, utilizatorul poate filtra textele disponibile după: (i) limbă (engleză L1, engleză L2, română); (ii) domeniul (cele 4 domenii: Lingvistică, Științe Politice, Științe Economice, IT); (iii) tipul de acces la text: open sau restricted (Figura 6). Au fost implementate o serie de soluții pentru a îmbunătăți timpii de răspuns ai procedurilor computaționale care gestionează cantități mari de date.

SEARCH: Interfața de căutare în corpusul EXPRES
Funcționalități secundare de natură informativă: Pagina principală („Home”) conține informații despre corpus („About”), adnotarea corpusului tutoriale pentru utilizatori („Tutorials”, pagină în lucru), publicații ale proiectului („Research”). Pagina „Statistici” oferă inclusiv vizitatorilor date generale, cantitative, despre corpus.

ABOUT: Informații generale despre corpusul EXPRES
CORPUS DOCUMENTATION: Informații despre procesarea corpusului
Funcționalități avansate în backend pentru contul admin: Interfața backend disponibilă pentru administratorii autentificați (echipa de cercetare DACRE) oferă instrumentele digitale pentru gestionarea textelor stocate în baza de date și a metadatelor asociate și oferă, de asemenea, un mecanism extins de statistici care acoperă tipologia textelor și caracteristici ale datelor (cuvinte, caractere, limbi, domenii și n-grame).
BACKEND: Pagina de administrare a metadatelor pentru corpusul EXPRES